

Demystifying the Generative AI Iron Triangle of Quality, Speed, and Cost
How to optimize your generative AI apps for speed, quality, and cost

Let us help you understand and navigate decisions around the three durable aspects of any generative AI application you are developing, 1) quality of the generated responses, 2) speed of your application as perceived by your customers, and 3) cost of running your application. This is the Iron Triangle of generative AI.
The Iron Triangle is durable over long time horizon as your customers will always care about quality, speed, and cost. So it is worth investing time in getting these right. However, optimizing one aspect usually means trade-offs in the other two, so the Iron Triangle analogy. We will help you make informed decisions when making the right trade-offs based on your use cases, resources, and target audience.

Importance of speed
Key takeaway: For most use cases you will benefit from optimizing for speed of your generative AI application. Speed and lower cost are related, speed yields higher conversion, and speed can also convert to higher quality.
Speed relates to conversion: Every 100ms of latency impacts conversion rates by 8% on desktop and as high as 30% on mobile.
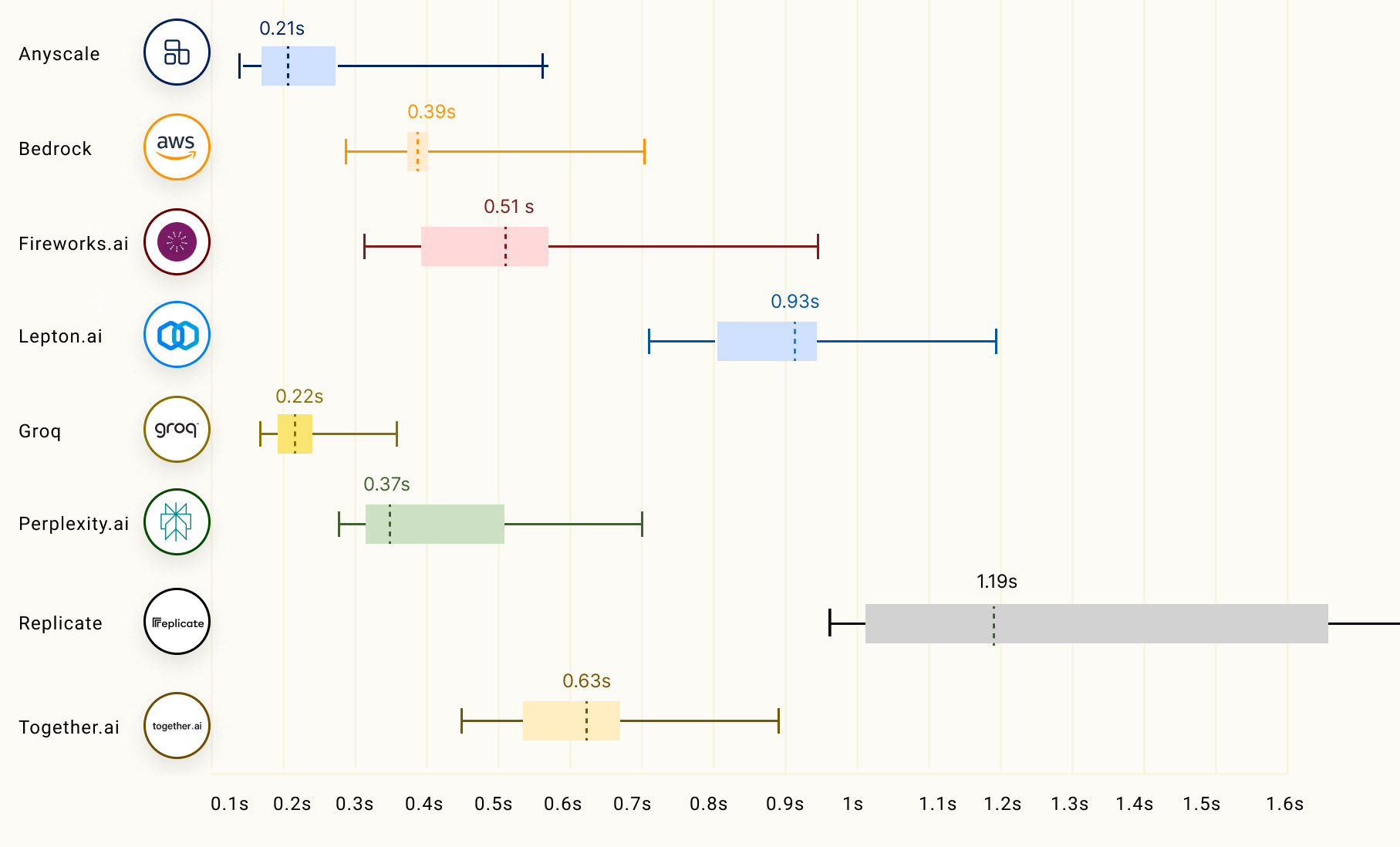
Time To First Token (TTFT): This is the pause before response from an LLM. This is important for streaming use cases like voice forward interfaces similar to Alexa or Siri. TTFT is also important when chaining one LLM response to another where the receiving LLM can start processing the first few tokens received. Following chart compares various LLM hosting providers based on llmperf leaderboard for TTFT, when running 70B models.
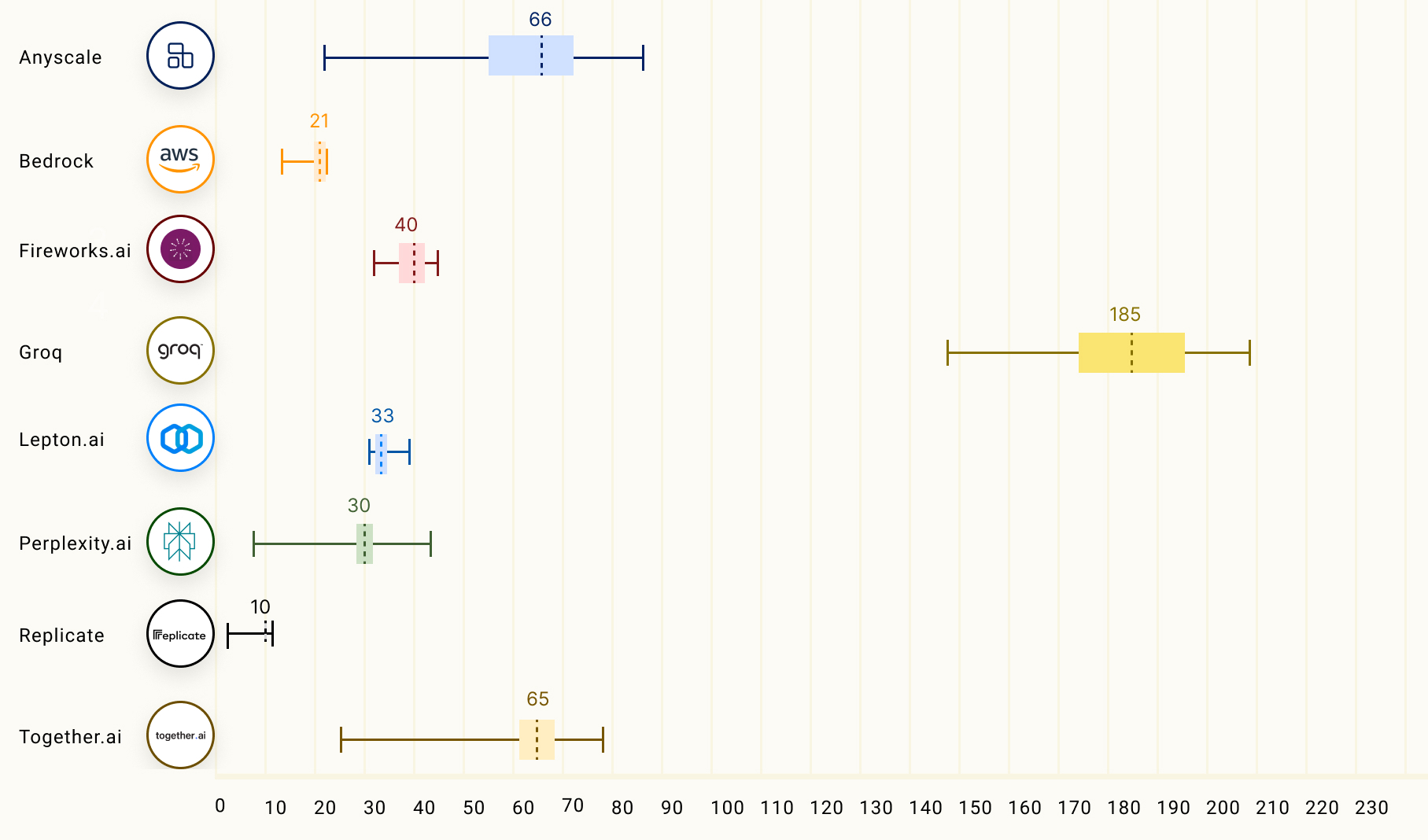
Tokens Per Second (TPS): Also called throughput. This is the rate of tokens streamed at the user interface. This is important for use cases where entire response needs to be presented to the user for it to be useful. An example is, solution explanation for a math problem which presents the solution in the end of the response. Following chart compares various LLM hosting providers based on llmperf leaderboard for output tokens throughput or tokens per second, when running 70B models. Groq using custom Language Processor Unit (LPU) chips leads the pack by a solid margin.
Round-Trip Time (RTT): This is the true measure of latency as perceived by the end user. From receiving the input prompt from a user to completely rendering the response back. Of course TTFT and TPS play a role in RTT reduction.
Reflection: You can turn speed into quality using reflection. LLM reflects on its own output and iterates a better response. Three reflection iterations gets an LLM response better by a model generation.
System prompt: A quick solve to reduce RTT is to use a system prompt to instruct the LLM responses to be crisp. Fewer tokens in response means fewer processing cycles. In a chat or conversational interface this matters even more both in terms of reducing cognitive load for the user as well as optimizing the size of the context. This has another side benefit of having smaller history in the context. It reduces “needle in haystack” problem, to find something specific, highly important, in a large history of text within an LLM context. An example is a dialog between a user and an LLM app answering questions about a retrieved blood work. When asked for value of a specific test, the LLM has to respond accurately.
Our subscribers can use the GenAI Techne System low-code package to instrument multiple models for latency and response size.
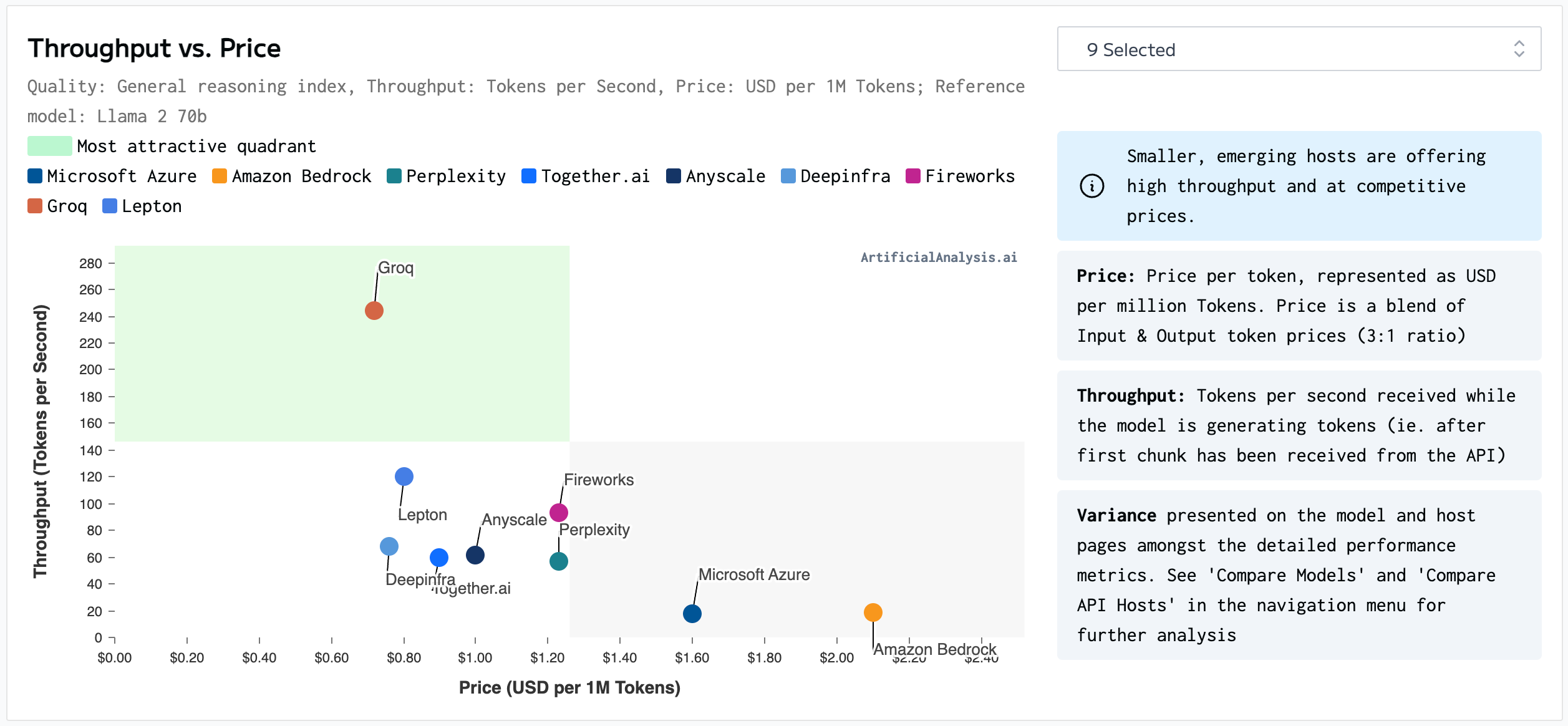
Cost leaders in Cloud may not be so in LLM
Key takeaway: LLM cloud hosting space is churning on throughput, price, and model selection. Avoid lock-in into one provider and build a multi-provider strategy for your generative AI application. Cloud cost and scaling market segment leaders may be playing catchup when it comes to LLM hosting.
Javons Paradox: Every decade, compute gets 1,000 times cheaper. People spend 100,000 times more. They spend 100x more as a result of compute getting cheaper. However, we are not there yet when it comes to GPU intensive LLM workloads.
Hyperscalers: AWS, GCP, and Microsoft Azure are still too expensive to build long tail applications. GPU is one of the main expenses. This is primarily due to GPU’s HBM (High Bandwidth Memory) which is very limited in supply. Customers spend $1 to $10 per million tokens. We need to drive the cost down by 10x to remain viable. What is interesting is that the hyperscalers are offering the lowest throughput for hosted LLMs when compared with new entrants like Groq and Fireworks.
Groq: A relatively new model hosting entrant that demonstrates promising results both on throughput as well as price. However, at the moment the model choices on Groq are limited.
According to their website, Groq has invented the LPU Inference Engine, with LPU standing for Language Processing Unit™, is a new type of end-to-end processing unit system that provides the fastest inference for computationally intensive applications with a sequential component to them, such as AI language applications (LLMs).
The LPU is designed to overcome the two LLM bottlenecks: compute density and memory bandwidth. An LPU has greater compute capacity than a GPU and CPU in regards to LLMs. This reduces the amount of time per word calculated, allowing sequences of text to be generated much faster. Additionally, eliminating external memory bottlenecks enables the LPU Inference Engine to deliver orders of magnitude better performance on LLMs compared to GPUs.
Quality is being given away
Key takeaway: Quality is being given away by pre-trained open source models. What differentiates is how you optimize on speed and price for your LLM based application.
In general optimizations which help improve speed also reduce cost while reducing quality. So, models like Mixtral 8x7B, achieving top 6 quality with number 3 rank for speed and number 1 in price, represent great value.
Mixture of Experts: Mixtral achieves this using a Mixture of Experts architecture with multiple 7B models working together to achieve the speed and price of smaller models while approaching the quality of larger models.
Following chart compares the Iron Triangle based on long prompts (~1,000 input tokens) and multiple (10) simultaneous API requests on these models.

Next. let us break-down the complexity of this trade-off decision by first principles as these apply to Large Language Models specifically and the field of generative AI in general.
First principles of Large Language Models
Key takeaway: Quality comes at a cost. Larger models require more compute at runtime. Observe law of diminishing returns to balance your quality requirements vs speed vs cost.
Neural network: This is a broad concept that encompasses a wide range of models designed to mimic certain aspects of the human brain's architecture and function, enabling machines to learn from data. Neural networks consist of layers of interconnected nodes or neurons, where each connection has a weight that is adjusted during the training process. These models are used for various tasks in machine learning and artificial intelligence, including classification, regression, clustering, and more. Traditional neural networks, especially those used in NLP (Natural Language Processing) like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks), process input data sequentially. This sequential processing can lead to difficulties in learning long-range dependencies in the data.
Transformer: This is a specific type of neural network architecture that was introduced in the paper "Attention is All You Need" by Vaswani et al. in 2017. It represents a significant departure from previous sequence-to-sequence models used for NLP tasks. The core innovation of the transformer architecture is the self-attention mechanism, which allows the model to weigh the importance of different parts of the input data differently. This mechanism enables the model to process all parts of the input data simultaneously (in parallel), significantly improving its ability to learn long-range dependencies and reducing training times.
Parameters: In neural networks, including LLMs, parameters are the weights and biases that are adjusted during the training process. The text LLM learns the correct values of these parameters through exposure to vast amounts of text data, enabling it to understand and generate human-like text.
Memory: The runtime memory requirements for running a model inference increase with number of parameters. The 7B models generally require at least 8GB of RAM, 13B models require at least 16GB, while 70B models require at least 64GB of RAM.
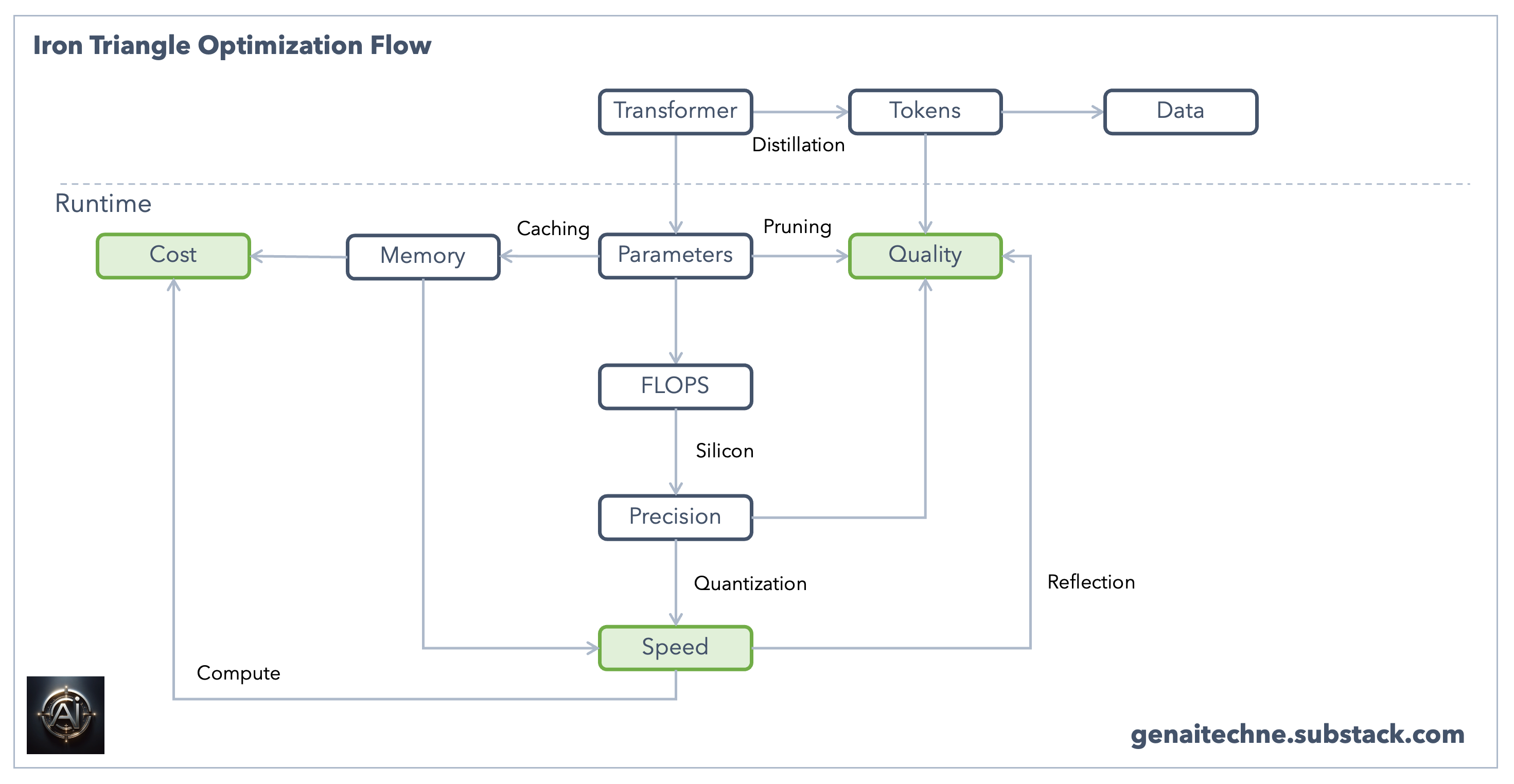
Distillation: Distillation is a technique where knowledge from a larger, more complex model (teacher) is transferred to a smaller, more efficient model (student). The student model learns to mimic the behavior of the teacher model, achieving comparable performance with a fraction of the parameters.
Pruning: Removing less important weights or neurons from the model. Pruning can be structured (removing entire channels or layers) or unstructured (removing individual weights), leading to a more compact and efficient model.
Caching: For models in deployment, caching previously computed hidden states or other intermediate computations for reuse can save significant computation time, especially for repetitive or similar inputs.
Quantization: Quantization is a technique used to reduce the precision of the weights and biases in a neural network from floating-point representation to lower-bit representations, such as 16-bit or 8-bit integers. This process helps in reducing the model's size and speeding up computation, making it more efficient to run without significantly compromising its performance.
Scaling Laws of LLMs
Key takeaway: Scaling larger models requires scaling training tokens proportionately. While quality improves with larger models, cost of training and inference increases, and speed of inference reduces.
The paper Training Compute-Optimal Large Language Models (Hoffmann et al., 2022) investigates optimal model size and number of tokens for training a transformer language model under a given compute budget.
Model parameters and training tokens: The paper finds that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled.
The paper also notes that current large language models are significantly undertrained, a consequence of the recent focus on scaling language models whilst keeping the amount of training data constant.
Training Loss: During an LLM training the training loss is computed based on an objective function, also known as a loss function or cost function. This function measures the discrepancy between the model's predictions and the true outputs. A decreasing training loss over epochs (iterations over the entire dataset) indicates that the model is improving its predictions.
FLOP: A Floating Point Operation (FLOP) refers to an operation involving floating-point numbers, which are numbers with decimal points used to represent real numbers in computing. FLOPS refers to number of FLOPs per second. A teraFLOPS is a trillion FLOPs (10^12). The popular LLM training Nvidia GPU 80GB A100 Tensor Core performs 156 teraFLOPS at FP32 precision and 312 teraFLOPS are FP16 precision.

The paper finds a clear valley in loss, meaning that for a given FLOP budget there is an optimal model to train (left). Using the location of these valleys, the paper projects optimal model size and number of tokens for larger models (center and right). In green, the paper shows the estimated number of parameters and tokens for an optimal model trained with the compute budget similar to the popular Llama 70B parameters model trained on 2T tokens.
Another important observation is that as long as one has the FLOPs and training tokens we can train larger models where training loss (quality) keeps improving. Of course one has to balance this increase in quality with diminishing returns based on cost of training larger models, reduced speed, and increased cost of inference for larger models.
The following table from the same paper can be used as a checklist when selecting pre-trained models to ensure they have been optimally trained based on their sizes. For example Llama 2 is a 70B parameter model is trained on 2T tokens. This matches the row four data in this table.

If you are thinking of training your own model the FLOPs mentioned can be understood as follows. Row 4 in above table is Llama 70B equivalent and it takes about 6,000 A100 GPUs running for 12 days or roughly 1e+24 FLOPS to train Llama 2 70B. That costs around $2 million (source). This highlights the value of open source pre-trained models. Most businesses would want to start there for custom LLM requirements instead of pre-training their own.
Data is the new oil
Key takeaway: While large data corpus (training tokens) means one can train larger, higher quality models, there is a trade-off in terms of data acquisition costs and future techniques which may train models on smaller datasets which may disrupt the current scaling laws of LLM.
Lets spend some words (or tokens) on talking about the other side of the coin with FLOPs on one and data on another.
An average book is between 200 to 400 pages. That translates to about 100,000 words. Usually 1 word is equivalent to 1.3 tokens, however for simplicity lets consider them equal. So for training the smallest 400M parameter model in our table above, we will need more than 60,000 books worth of data. The entire Wikipedia English is 4.5 billion words so it still falls short of requirements to train the smallest model in our table!
So, Foundation Model developers have to look outside of Wikipedia for data to train their models. Another reason in addition to the sheer volume of data requirements is the shape of the data. Wikipedia is long form definitions, mostly factual information about a topic. Reddit on the other hand has conversational style data between humans. This is valuable for LLMs to train on human conversations to learn how to converse like humans. So valuable that recently Reddit reported that it has signed a $60M annual licensing deal for its content with an AI company. OpenAI offers between $1 million and $5 million a year to license copyrighted news articles to train its AI models.
Having said that OpenAI among others is researching how to train LLMs on smaller datasets with same outcomes in quality. The analogy is that humans do not read thousands of books to become experts in a subject. Here is an example of a research which may be related to this. The research from OpenAI reports “super” summarization of a 29,000 words book into 136 words.
Prototype to production strategy
Key takeaway: Recommendation from industry experts is to 1) use the best proprietary models for understanding capabilities, 2) experiment with the latest, most optimized open models on consumer grade hardware to match capabilities from state of the art, and 3) select the best throughput vs price among hyperscalers for production.
Step 1 - Proprietary: When starting your generative AI project you may want to start by exploring the state of the art capabilities required by your use case. OpenAI APIs are a good place to do so. You can try multiple model variants offered by OpenAI to understand the art of the possible.
Step 2 - Local: Once you are satisfied with the capabilities, your next stop may be open source models. Ollama enables you to download quantized versions of top open source models which run comfortably on modern laptops. You can experiment with these models without incurring any OpenAI API costs or increasing your cloud billing.
Sometimes you will be surprised that open source is ahead in state of the art capabilities. For example, visual question answering models, where you could upload an image and ask questions about the image, were available in open source before top LLM vendors launched multimodal.
Another reason to play with Ollama models is to experiment with model size variants to find the smallest, fastest, least costly to run model for your use case.
Step 3 - Cloud: Once you are ready to go production you can head to your favorite cloud provider and find the managed variant for the model you chose in step 2 or if the you desire higher quality then go up a notch on the precision for a larger model variant. Compare speed, quality, cost, then iterate based on your requirements.
Our subscribers can use the GenAI Techne System low-code package to compare GPT models using OpenAI API, AWS managed LLMs, and Ollama models running on their laptop.

We achieved a lot in this article. We went from appreciating the Iron Triangle to determining an optimization flow based on LLM first principles. We were also introduced to the GenAI Techne System low-code package which codifies these best practices for you to try on your own.